
Welcome to Smart Home Forum by FIBARO
Dear Guest,
as you can notice parts of Smart Home Forum by FIBARO is not available for you. You have to register in order to view all content and post in our community. Don't worry! Registration is a simple free process that requires minimal information for you to sign up. Become a part of of Smart Home Forum by FIBARO by creating an account.
As a member you can:
- Start new topics and reply to others
- Follow topics and users to get email updates
- Get your own profile page and make new friends
- Send personal messages
- ... and learn a lot about our system!
Regards,
Smart Home Forum by FIBARO Team
Search the Community
Showing results for tags 'hc2 issues'.
Found 1 result
-
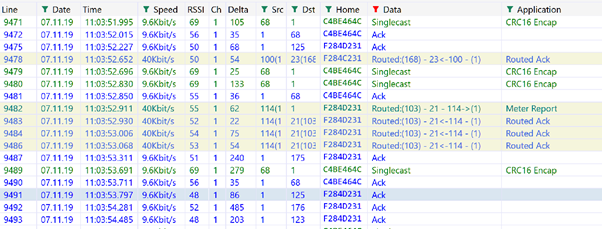
Please read the following with the understanding that I have well over 100 z-wave devices, in fact I will soon be approaching and (if all goes well) exceeding 200. If you have a smaller system you may never experience the following, although with some unfortunate parameter settings it's still possible. Also, the issues described below may be resolved with time. Both my HC2 are currently on v4.560. Since not long after I installed my first HC2 I have had an extensive and generally growing list of unresolved issues. Many of which I have posted on this site, many of which I have just kept to myself. For well over 5 years I have considered the system I installed to be broken, not fit for purpose or for mass consumption. Why? Have you experience or are you still experiencing any of the following? - Zwave lags - sometimes you go into a room and the automated lighting turns on in a couple of seconds, sometimes it takes 5 seconds to come on, sometimes 10 seconds, sometimes 60 seconds, sometimes you just don’t wait long enough to find out and manually turn the lights on yourself. Sometimes lights don’t automatically turn off (in the end I wrote a scene to sweep through my lights to keep trying to turn them off each 15 mins) - HC2 freeze – after a number of days my HC2 just freezes up. Nothing I can do other than a hard restart from the 2x HC2 will resolve it or a soft reboot through LUA before the problem happens. Once upon a time I could run an auto reboot scene every 7 days, there was a time I HAD to run it every single day, recently I was rebooting every 3 days - Random behaviour* – sometimes heating relays turn on, sometimes they don’t. Sometimes I have to click 2 or 3 times to get a light to turn on, sometimes once. Sometimes I have to click 2 or 3 times to override automated lighting scene - BUI and MUI – very often do not reflect reality. Light levels and RGBW colours randomly reflect reality correctly to the point where I simple ignored them when it came to light levels and colours - Including/Excluding devices – multiple attempts required to add / delete devices, sometimes taking hours to get a few devices added Random behaviour* Even after applying everything stated below and now (barring random DB crashes) having a relatively stable HC2/system, I still have many devices that do not work as expected e.g. devices do not turn on or off consistently, sometimes requiring many (more than 3) clicks to respond; despite there being no zniffer activity at the point of clicking. In the end I have concluded that because I was adding these devices when my zwave network was in total mayhem (usually more than 40 frames per second of activity when nothing was actually happening in the house), that the devices were not added correctly. I think this assertion is true. I have in many cases found it very difficult to fix. The best resolution has been to: 1. add the device again through inclusion 2. delete the device through exclusion, checking zniffer to make sure the device is actually deleted i.e. no more comms from the nodeid 3. add the device again from scratch, checking zniffer to ensure a new nodeID has been added Why complete step 1, not just 2 and 3? It seems to work better. If I try to just delete the device, in many cases they they just won't delete. Adding the device, even though it's in the interface already seems to do something to stabilise it. Perhaps a "read configuration" or "soft reset" or "hard reset" would also work, however many of these devices I have found seem to be in a bad state, so I have gone for the scalpel approach, cut it out and replace it new. I thought I would share this as it's a new step I have identified to improving my system and it may be something you need to do if you system gets into a bad a place as mine was and you are still adding devices during this period. The good news is that, for now, the fix seems to work. All of the above with a still substantial list of other bugs leaves one to wonder what have I done wrong. It also consumes days, weeks, months, years of checking and rechecking code and config, over and over again and, rebooting the HC2s. Sometimes things get better, sometimes they get worse, sometimes they stay the same, but you're never really sure what you did to change the state of play. How is it that my automated lighting override scene works sometimes but not other times? Did I forget to add this particular switch to the scene? But wait it is working now after the 3rd click. What on earth is going on?!?!?! The short of it is, you end up living in a house where you kind of accept that the system is rubbish, but as so long as (most of the time) there is hot water for showers and baths, the heating works and the lights come automatically it is good enough. I came to the conclusion at the start of this year that I had to leave Fibaro, or at least that I had to leave my 2x HC2 behind. In the process of researching for other options I started talking to @robmac who has all but left his HC2 behind. What a great loss for the Fibaro community. Fortunately after an epic journey into the abyss this story has a good ending and I want to share this good ending with you. Firstly however the credit for this does not go to me. I am just another Guinea pig following advice entirely from the members of this forum. Two people mainly: one that is still fully using Fibaro equipment (thankfully) @petergebruers and of course @robmac. Others along the way have also made great breakthroughs and will be referenced below: So what’s the root cause of all of the issues I summarised above? Zwave traffic, and too much of it. Many times over the years Fibaro Support have logged into my 2x HC2 and every time I get the same comment… wow, you have a lot of traffic. On rare occasions I have been advised to do something with 1 or 2 devices and it usually improved things. Most of the time nothing was forthcoming. So, if you are experiencing any of the stability issues I have mentioned, what can you do about it? Two things: 1. Buy a Zniffer and see what is REALLY happening with your zwave traffic and then address those issues 2. Make config and other updates to your system to reduce traffic Is it possible to do 2 without 1? - Yes, but you will never know for sure if there is still some rogue issue out there Is it hard to get a Zniffer up and running? - Absolutely not. It took me about an hour to get it up and running. Once you realise that the Zniffer captures node id’s and you can find these by looking at the api: http://[HC2 IP ADDRESS]/api/devices. It’s relatively easy to START see what’s happening. To fully understand Zniffer takes more work though. Let’s begin: What I have done to get my system from broken to working? Zniffer 1. I ordered and flashed a UZB3 USB zniffer. Installed the ZWaveProgrammerSetup.msi software on a Windows machine and started sniffing. Thank you to @tinman for posting this: PS: There are many suggestions here that you can do without a Zniffer, however if you choose to not get one then at the end of the day you are making changes without really knowing the impact. At the end of this post I will suggest some other tools that you can use in place of a Zniffer, however be aware that they will not give you the same detail as a Zniffer. You will be limited to what the HC2 exposes through the API which is not the whole picture. Given the size of your system and the size of the issues you are facing you may choose to not get a Zniffer, however if you have a larger system with issues, I would expect that you will want one eventually. Reducing Traffic – Sanity Check Script 2. Some devices by default send a lot of energy and power data updates. With the Zniffer you can check for any devices going absolutely bonkers on the network i.e. frames (the transmissions that make up an action) just keep repeating over and over again rapidly. Now the question is what to do. One path is to diagnose and fix them one by one or else (with or without a Zniffer) you can start by running @petergebruers Sanity Script: This script will tell you (for many devices) sane parameters for reporting energy and power. Personally I have made much more drastic changes to my parameters. In almost all cases I have turned off energy and power reporting, on devices that allow me to do so, as my number one goal is stability. Once I have a stable system I may consider what to turn back on again. Reducing Traffic – Other Bugs/Issues 3. Once you have run the Sanity Script and made necessary parameter updates you can look again at the Zniffer. You may find other issues. I had at least 6 of them. They were Fibaro Double and Single Switch modules where I had turned reporting off. By doing this a bug is exposed where the devices spam the network constantly to the point where my system was dealing with a constant traffic of over 40 frames per second. In the first instance you can set parameters to default to stop it. The issue appears to be with setting certain parameters: - Fibaro Single Switch, as soon as you set parameter 53 = 0 to disable it or 320 to set it to the max enabled value, the reverse spamming begins with what looks like the controller sending single sided 9.6k frames every 1000ms. When I set 53 = 319 the spamming stops! - Fibaro Double Switch: I haven't tested extensively, but by setting parameters 53 and 57 to 319 the spamming stops PS: You need to set the above parameters to 31900 if you are doing this using LUA, else 319 through the interface and to make things interesting I have found 2x Fibaro Single Switched where I can set parameter 53=0 and the spamming doesn't happen. Go figure. If you have a Zniffer you can instantly see the impact of buggy parameter combinations. Without you will need to rely on others sharing their own experience and with some of the tools mentioned at the bottom of this post. Once you have tuned the traffic down, assuming you did have a traffic issue in the first place, then you can move onto other things. I went from 25-45 frames per second down to much less than 1 frame per second now when there is little activity and I haven’t seen anything much above 10 frames per second when there is activity, but I’m still testing so that figure may change. I have been advised by @petergebruers that as a rule of thumb zwave (when using the HC2) can do around 10 commands per second, so think about this when writing your LUA scripts. Please don't confuse the individual frames that you see in Zniffer with a single command. A command will show as two or more frames. Reducing Traffic - Global Polling 4. Given the size of my system I have given up on the idea of global polling. I set every device to “device excluded from polling”. Again, this may not be something you want to do, but for me it is stability above all else and then I can add back functionality one day if I feel l really need it… which I doubt will be the case TBH. There is one exception to this rule: I did keep polling on for important devices which currently are all the relays that control my heating (boiler, radiators, underfloor heating). Polling is set to 5400 to ensure that every 90 mins there is a poll on those devices. Run this code to see what the status of Wakeup and Polling is by device. You will need to run it for each HC2 in your system (if you have more than one), thanks again @petergebruers for sharing this code: What is polling? The HC2 will connect with the device to check things like status and retrieve information such as energy usage, temperatures. This all adds to zwave traffic, but for some critical devices it’s worth the extra traffic. This is an excerpt from Robmac's post on another forum, worth reading in the context of configuring polling: "Reducing polling down to virtually nothing rather than no polling has one small advantage. It provides the network with a self tuning capability. The polling tests the routes and if they are not good and stable the routes slowly improve to the most stable route available. If there is no stable route you will also have regular traffic that shows up in your zniffer with retries/explorer and even application retries. How regularly you poll or how many nodes you poll is your decision. In time I have reduced all of the nodes I poll to a period of 10 days. I have also tweaked the binding in the past so a no polling option is possible and 80% of my nodes were no longer polled with no adverse effects. It was just not required." Reducing Traffic (and increasing personal sanity) - Phantom Association 5. I thought it had gone away, however when I was setting associations on Fibaro RGBW modules recently I saw associations selected on random devices, so I ran this script which I thought Fibaro Support gave me years ago, however if it’s yours @jakub.jezek, thank you for the contribution: If you run this it will reset all associations including those you might want to keep. There is room to improve this script to reset only “phantom” associations across ALL devices by including a list of hardcoded exceptions that should remain. This is something to look into later at which point this scene could be run once a week (for example) in the early hours to keep the system clean of phantom associations until this issue is FINALLY resolved by Fibaro. Update: @petergebruers has confirmed that v27.27 of the Fibaro RGBW firmware really does fix the phantom association issue (with the right parameters set), so please consider this when deciding your personal course of action. Reducing Traffic - Scenes & VDs I have done or am in the process of doing the following. You may want to do something similar. Thanks to @robmacand others for these suggestions: 6. Adding sleeps - Add a fibaro:sleep(x), where x could be ~100 in between each fibaro:call to allow time for each command to be executed; this may help by not creating zwave bottlenecks. I have been advised by @petergebruers that as a rule of thumb zwave (when using the HC2) can do around 10 commands per second, so think about this when writing your LUA scripts. 7. Staggering autostart scenes - Add a staggered fibaro:sleep(x), where x could be ~60000+ with appropriate gaps in-between scenes, to all autostart scenes, so they don’t all collide with each other and add load when the system first starts up. Update: some additional notes from @petergebruers as to why to add the delay on boot "(1) the network is not ready (2) if you ever write a bug that crashes the HC or makes login impossible - you'll thank me for suggesting that delay". If you have a Zniffer you should check to see how long your HC2 scan your devices on startup to inform you as to how long the delay should be. 8. Remove code from the VD Main loop - The VD main loop runs constantly every 3 seconds. Instead move the code to a button (which you will need to add to the VD) and press the button each time you want the code to run 9. Check state before changing state - In LUA always check the state of a device before changing the state of a device - I've been using this one since the beginning. It will help reduce zwave traffic. 10. I am sure there are more out there, please share and I will add to this list.... General Tidy-up & Tips 11. Much can be said for a general tidy up: - Dead Devices - Delete dead devices not used anymore - Firmware - Update firmware on devices; this is something I simply could not do before as my network was in constant turmoil - “Waiting for wakeup and synchronisation” – this is an issue on 1/3 to 1/2 of all my devices. These were introduce in an upgrade along the way and seemingly need to be addressed one by one. The only way I have been able to get rid of this issue is: read config, soft reconfig and then come back to it later if that doesn’t work eventually maybe devices need to be excluded and included again. I am still waiting on Fibaro Support to come back with a solution to this… - Clean Database: Ask Fibaro Support to log into your machine and clean your database - Network Connection Type: A few months ago my HC2 were locking up on a daily and sub-daily basis. I finally figured out what was going one. Despite setting a static ip address on my router for both HC2, in Configuration => Lan settings =>Connection Type was set to: DHCP rather than Static IP. Setting it to Static IP stopped this issue from happening. The Heavy Stuff - Improving your network A huge thank you to the resident zwave gurus @petergebruers and @robmac for all of the information that I am summarising below of which there is always more to learn, but this should give you enough to get you going: Update: Some additional tips from @petergebruers: "Please be warned that you are working with a source routed network", the hops are called "repeaters" because they are "NOT routers" and when thinking about how the zwave mesh network works, you should forget everything they know about IP routing. 12. Understanding Zniffer a little better I have been advised by @robmacto not focus too much on routing. Zwave routing can be weird. Routing transmissions look like this in zniffer (103)-21-114>1, where 103 is the source device and 1 is the destination controller, with 21 and 114 being the routing devices) and consider what can be done with these. Is it possible to move the device 103? Can you move the device antenna (if it has one)? In my opinion (putting routing/repeating aside) you should however try to resolve explorer frames and single sided messages that keep repeating on the network. So what types of issues you can detect with Zniffer? I mentioned some above, if you are seeing the following then you know which devices to target: a. Explorer frames – This happens when all else fails and a device cannot be reached and caused a lot of zwave traffic whilst the controller is trying to find the device. You need to consider things like the device locations, the direction it’s antenna is facing (if it has an external one), can it be moved, can your HC2 be moved closer, can another device be put in between to improve connectivity. b. Single sided 9.6k – This was happening when I had buggy parameter settings on Fibaro Switches that were spamming the network. You see them as the blue records at 9.6k below. Good communication happens at 40k for the 300 series controller which is what we have in the HC2. c. Traffic overload: You may spot devices that just keep sending and receiving frames. Consider the parameters for these devices, is it just lots of energy and power reports, if so, do you need this frequency of reporting? And also check for the type of error message to come to a solution for dealing with this type of issue. Some quick tips on reading Zniffer output: - Src = source node, where 1 = HC2 - Dst = destination node - Home = you will only see one if you only have 1x HC2 - Speed = with the HC2 you will see either 9.6k or 40k as the HC2 cannot do anything faster, however the Zniffer will also report 100k (you will see 100k between Z-Wave Plus (aka ZW5) devices) with the right hardware (controller and device) and even 200k is possible. - RSSI = “Received Signal Strength Indicator,” is a measurement of how well your device can hear a signal There is a world to learn about with a Zniffer. I do not intend this to be a tutorial on using it. So far, the issues I have spotted have been easy to find as I have been looking for devices that are sending too many frames in a short time period. There is a much deeper world to explore for the inquisitive mind. You will most likely see CRC_ERRORs in the Zniffer output. The current consensus as shared by @petergebruers is that this is more to do with the location of your zniffer i.e. it is too far away from the device that the signal has come from and the Zniffer is reporting a CRC_ERROR. Until further notice it can be assumed to be something you can ignore. 13. Mesh Rebuild – Although it may be a painful thing to hear, it may be better to rebuild the mesh one device at a time starting with the major issues identified. FYI, I don’t plan to perform a complete mesh rebuild ever again. To do a mesh rebuild for just one device go to (Configuration => Z-Wave network => Mesh network re-configuration => select the individual device). If you are watching Zniffer you will soon see the mesh rebuild start and see what happens when a mesh rebuild occurs. You’ll learn something new just by watching Hint: I have seen two different types of process so far to date. So far I have only rebuilt the mesh manually on about 12-15 devices and the system is running infinitely better. I'm not sure you have to rebuild every device manually. I'd be interested to hear people's feedback in this one. Helpful updates from @petergebruers: 1. a tip of building a good mesh network, when starting from scratch, "strategically place your newest, fastest, mains operated devices that are NOT in secure mode and that won't be reporting a lot and won't be turned on/off a lot, FIRST" 2. You may have issues getting a mesh update to work, here are some possible explanations: - device is out of reach - it is sleeping - if you get "failed" the network might be busy or unstable - Even on a 100% OK network it can fail. Cannot tell much about it. It is not limited to the HC2, eg OpenZWave has that issue too 14. Relocating your HC2 - Sometimes just relocating your HC2 to a more central location can reduce the number of hops. My master HC2 in its current location has over 80% direct communication with the controller. My slave has only about 45% direct, so that’s where my focus is now. You may have to do a targeted mesh rebuild if the HC2 is moved a significant distance. 15. Moving Device Antenna – it has been reported by @robmacthat by just moving the antenna on a device it has improved communication. You can try doing this to see what happens and then do a mesh rebuild for that device. Also make sure you HC2 antenna is screwed on well to the controller. 16. Moving the Device – if you have the luxury, try moving the individual device and rebuilding the mesh network for that device Update from @petergebruers "yes and maybe [move] the devices around it or make educated guesses based on Zniffer. The controller might have better routes for other devices after this but those other devices do not get updated unless you do mesh update" 17. Adding a repeater - You can add a repeater in between the controller and the device and then complete a mesh rebuild to see if that improves communication eg resolves routing errors Z-Wave Rule of Thumb by @petergebruers "My Z-Wave rules of thumb: less than 5 modules, sometimes issues because not enough devices to cover all areas. Between 5 and 20...almost never issues. Between 20 and 50... sometimes trouble. Between 50 and 100 devices real "weirdness" starts and communication gets "fragile". Above 100 make sure you have the tools to diagnose network issues (ie Zniffer, you can make one yourself) or get in touch with a good certified installer to support you (I am and end user, not an installer). Know about CPU and memory usage. Follow this forum. I have participated in many topics regarding "delays" and it is never easy..." Tools to use if you don’t have a Zniffer Following are some suggestions of tools to use if you don't have a Zniffer. Z-Wave monitor helped me at the start of this year to get my system to "just" work from completely broken/unmanageable performance. Z-Wave Monitor, thanks @cag014 Z-Wave Analyser, thanks @cag014 I have used these tools and they helped me when I really needed it. They may help you. But please be aware that they are not a substitute for a Zniffer. Useful Links If you have connectivity issues with your HC2 you can check status using this: http://[HC2 IP ADDRESS]/services/system/servicesStatus.php Or run this scene from @petergebruers to get a dump of node id to master and slave device ids on your controller: If you want to find out details on devices including node id to device id mapping for when using the Zniffer: http://[HC2 IP ADDRESS]/api/devices Finally, I’ll aim to update this post with feedback plus additional detail that I learn along the way and apologies in advance if i've misstated something technical. I'm still learning myself.

- 53 replies
-
- 5
-

-

-
- zwave issues
- random behaviour
- (and 6 more)
